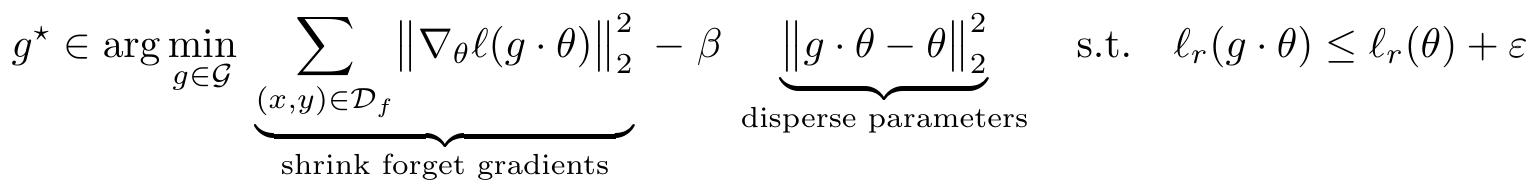ICLR 2026 · Rio de Janeiro


Weight Teleportation for Attack-Resilient Unlearning Protocols
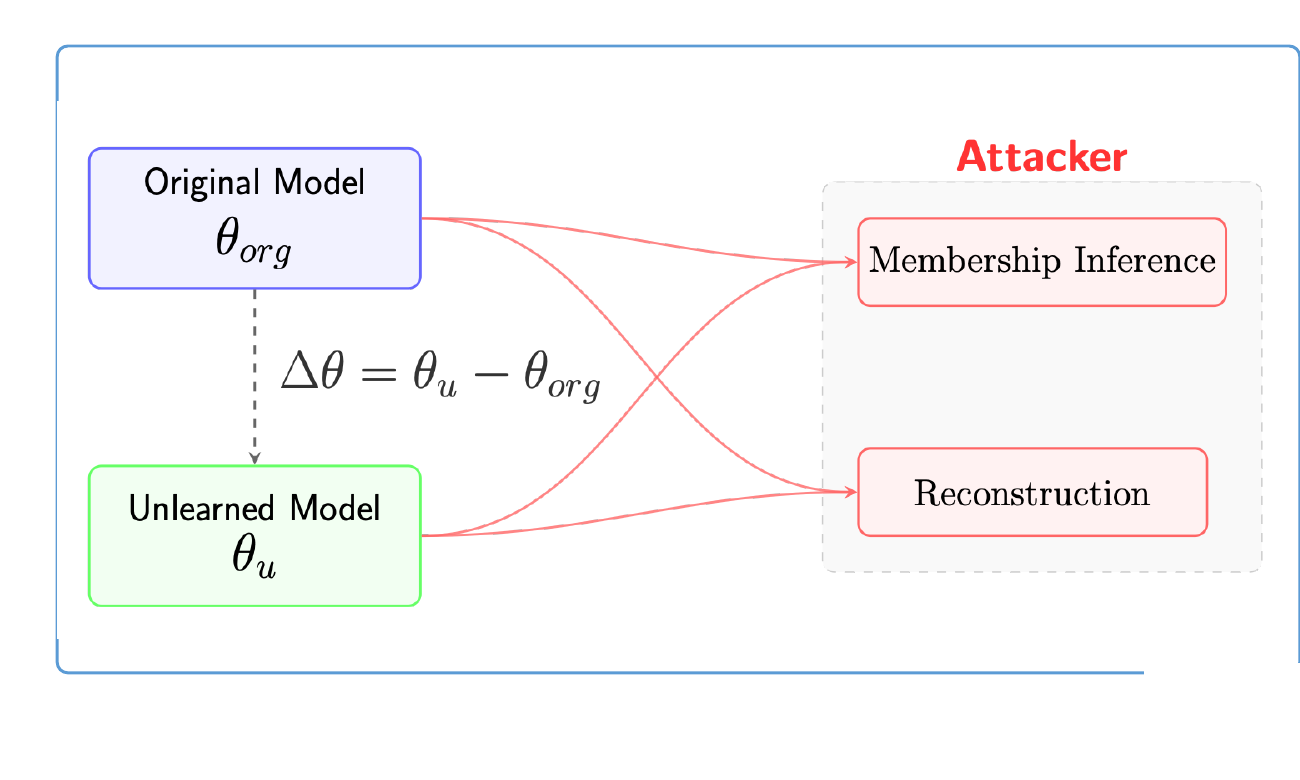
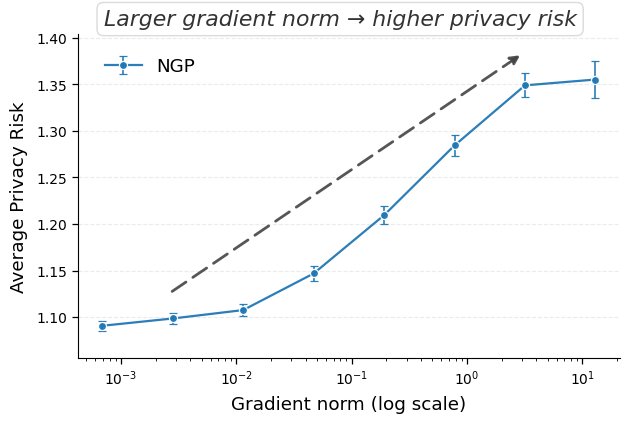
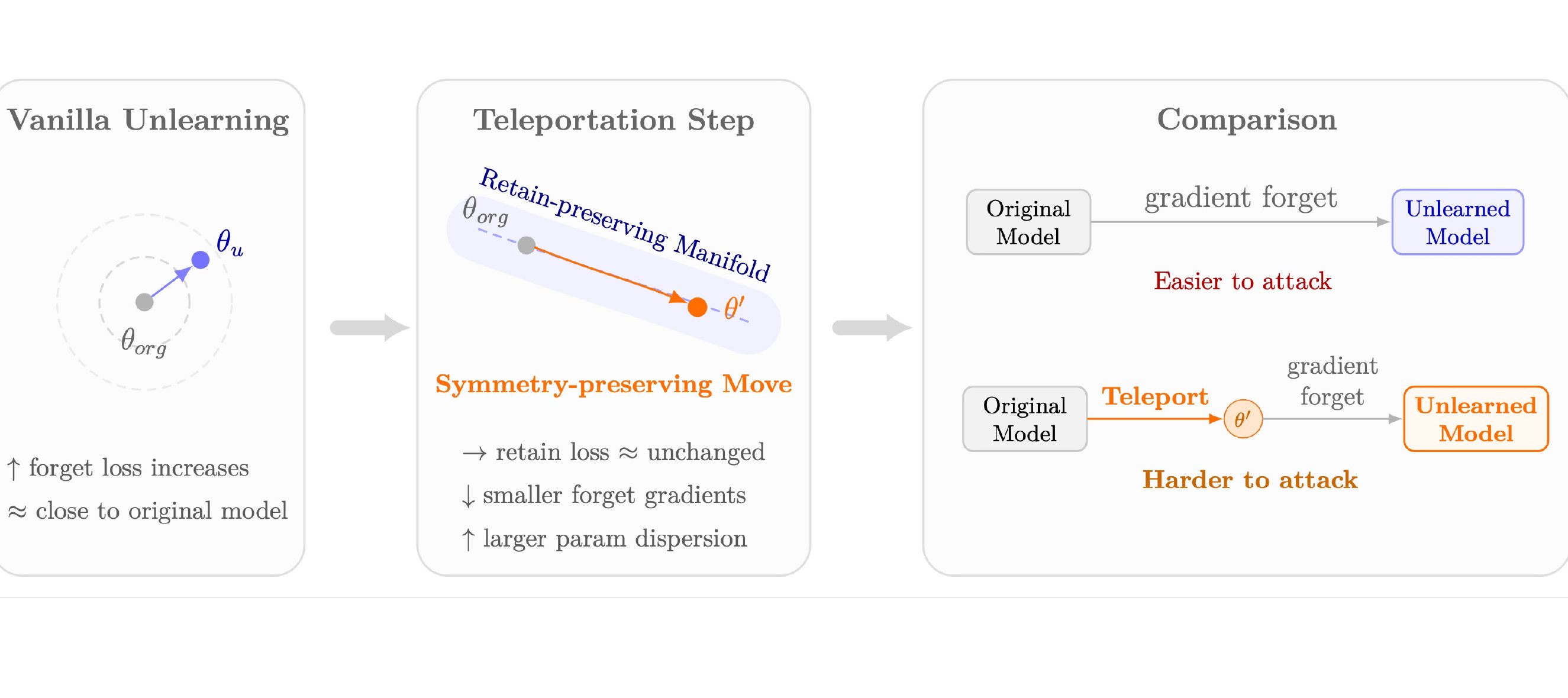
A plug-and-play symmetry defense that reshapes the geometry of approximate unlearning — reducing privacy leakage without retraining, added noise, or changing the unlearning algorithm.
1Imperial College London
2Dartmouth College